Python guessing game

Today, my task was to create a software in Python 3.0 and above, with 3 separated scripts:
- pclient.py file: Containing a player client, who tries to guess a random number generated by the server.
- aclient.py file: Containing an administrator able to see how many clients are playing simultaneously.
- server.py file: Containing my server whose main task is to pick a random number, open, bind and listen to different sockets.
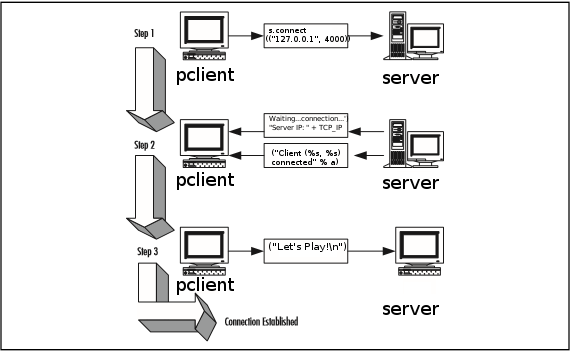
In order to do so, all 3 of my scripts must be able to safely and securely connect to each other via a 3 way handshake, method used in TCP protocol. Then the server will generate automatically a random number and open sockets for the “players”, and one separate port for one administrator.
The pclient’s will try to guess the number, and every time a new pclient starts to play, the server will notify my aclient that a new player has started to play. The aclient will then ask which socket has been binded and automatically save it in a list.
Lastly, when a player guesses the number, the server must be able to close his socket in order to finish the connection.
I will first explain some basic methods I had to use in order to do so, and then roughly explain what the 3 scripts do:
1. Server side
-I’ve opted for a multi-threaded approach, in order for my server to accept several secured connections simultaneously, and with different roles, then bind and listen to specific sockets through a 3 way handshake or else stop the connection. In order for my network to work properly, I needed my server to let one administrator connect at port 4001, and multiple players to be able to play at any time through port 4000.
-Then the server creates a random integer in a range from 1 to 30, and with a while loop (while the number was not correctly guessed) the game would go on.
With an infinite (while true) loop the server wouldn't stop listening to the port until the number had been guessed correctly.
2. Player
- The player will first try to make his secure three-way handshake if the connection is successful; he would then establish a connection, and ask the user to input manually a number. While the GuessNumber is false -it is to say not an integer between 1-30- he will repeatedly answer ("Pick a number between 1-30\n") since it is not a valid value.
In order not to create a conflict, only integers from 1 to 30 would be allowed as a valid input with a “try ” method; then if the number is guessed correctly by the user, it will print a message telling the user that he won, and then close the socket.
3. Administrator
-The aclient would then establish his connection with the server, and then make a list of all the players’ socket IDs’ connected to the server.
After launching the server, the admin gets connected, scans and saves all of the IPs and sockets, that are connected through a while true loop, therefore all of the players can now start the guessing game, in the flowchart below I explain the main functions:
Conclusion
The TCP protocol is a three-way handshake between the client and the server. Only when the three-way handshake succeeds, can the communication be established. And only then can the game start.
A pclient trying to connect to the server initializes the connection by sending a TCP packet, and the port to which it wants to connect (in this case port 4000). If the port is open on the server and is accepting connections, the server responds and informs the aclient.
The connection is established by the aclient sending an “(Admin-Greetings\n)” message through the final handshake (“who”). The port on the server is listed by the admin.
The client sends the first handshake using the ("You are now connected to the server!\n") message and the game starts.
If the server responds with a negative answer, that particular port is closed on the server and therefore becomes free to be re-utilized further.
Download the full script on my GitHub account.